이 글은...
Andrew Ng 교수의 Deep Learning 강좌 C1W3L05 까지의 내용을 정리한 것이다. 많은 입력 샘플에 대한 신경망 네트워크를 백터화 하는 방법을 설명합니다.
내용 요약
많은 샘플에 대한 벡터화
m개 샘플이 있을 때,
for i in range(m):
z_1[i] = W_1 * x[i] + b_1
a_1[i] = sigma(z_1[i])
z_2[i] = W_2 * a_1[i] + b_2
a_2[i] = sigma(z_2[i])이런 식으로 샘플을 순환하며 계산해야함을 알 수 있다. 당연히 for 문은 효율이 떨어지므로 벡터화하여 계산하는 것이 빠르다. 각각의 중요 벡터의 형태를 살펴보면 아래와 같다.
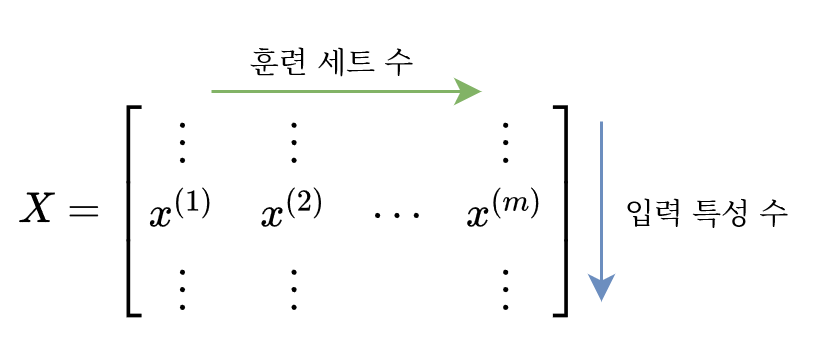
여기에 $W$ 벡터와 $b$ 벡터가 빠졌는데, $W$ 벡터의 형태는 (은닉 노드 수, 입력 특성 수)로 변함이 없다. 그리고 $b$ 벡터의 형태도 훈련 세트의 수와 상관없이 (은닉 노드 수, 1)로 똑같다. 대신 $b$ 벡터는 파이썬 NumPy의 브로드캐스팅에 의해 $Z$ 벡터의 모든 열에 연산이 된다.


식으로 표현하면 아래와 같다.
$Z^{[l]}=W^{[l]T}X+b^{[l]}$
$A^{[l]}=\sigma(Z^{[l]})$
레이어가 아무리 많이 쌓여있더라도 위 식과 같은 패턴이 반복된다. 레이어가 1층이든 100층이든 같은 방식으로 계산된다.
'연구 노트 > 머신러닝' 카테고리의 다른 글
| [TIL] 210413 - Deep LearniNg (~C1W3L09) (0) | 2021.04.13 |
|---|---|
| [TIL] 210410 - Deep LearniNg (~C1W3L07) (0) | 2021.04.12 |
| [TIL] 210405 - Deep LearniNg (~C1W3L03) (0) | 2021.04.05 |
| [TIL] 210401 - Deep LearniNg (~C1W2L18) (0) | 2021.04.02 |
| [TIL] 210331 - Deep LearniNg (~C1W2L15) (0) | 2021.03.31 |


